docker 搭 nginx、mysql、redis 服务
背景
最近重构项目快完成了,快要上线,用 docker 来搭一些项目依赖的服务,nginx、mysql、redis,下面记录一下步骤
nginx
拉取 nginx 镜像
1 | docker pull nginx |
编写 docker-compose.yml 文件
1 | version: '3' |
conf 文件配置静态文件服务
1 | server { |
最近重构项目快完成了,快要上线,用 docker 来搭一些项目依赖的服务,nginx、mysql、redis,下面记录一下步骤
1 | docker pull nginx |
1 | version: '3' |
1 | server { |
最近接手的 App 重构项目,进入到第三方平台接口对接模块,看到只有一个接口文档,里面没有接口地址,没有协议说明,只有一些字段说明,一眼看去有点懵,不知如何下手。
于是翻看原 node.js 写的代码,找出了接口地址,发现是 wsdl 后缀,然后立马复制 url 用浏览器请求一下,发现本地打不开,原来是做了 ip 白名单,只允许服务器的 ip 请求,这就有点尴尬了,只好用 curl 命令在服务器上执行,发现返回了一段看不懂的 xml,经过谷歌搜索才知道这是传说中的 webService 接口。
还是第一次碰到 webService 接口对接,只能依赖搜索引擎来上手了,于是我就在 wsdl、soap、envelope、UUDI 等专业名词上转来转去了,半天过去都没明白正确的开发姿势是什么。
后来发现有个soapUi 的玩意能分析 wsdl 文件,提取服务接口地址参数等信息,再后面发现原来可以用 IDEA 根据 wsdl 地址生成 soapClient 代码,利用生成的代码即可完成服务远程调用。
知道了正确开发姿势,就开始动手了,然而事情并非那么简单,还是遇到了一些问题,下面记录一下。
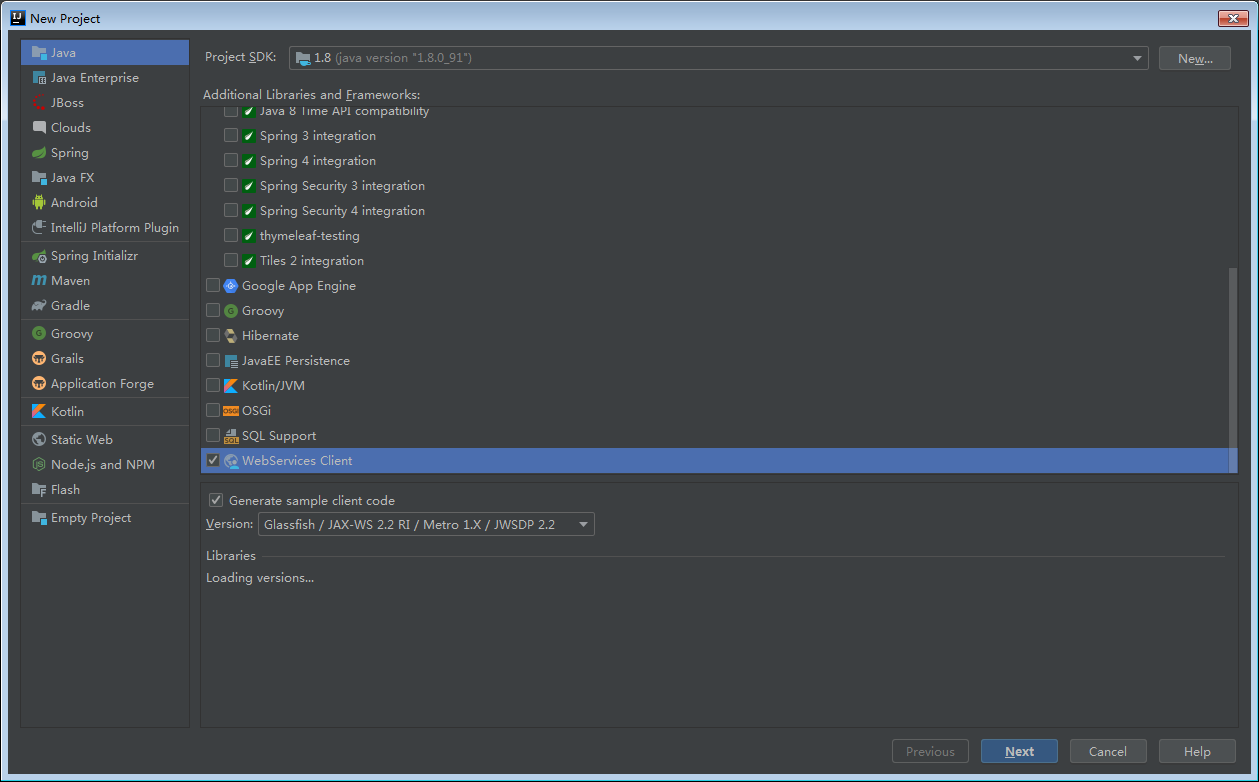
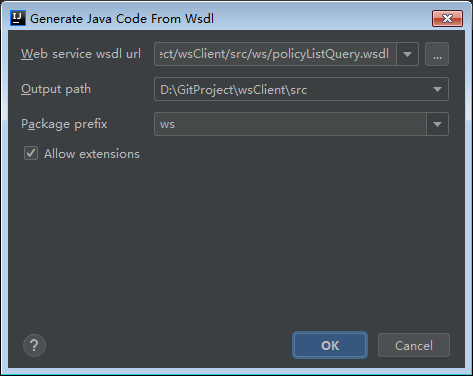
由于用 IDEA 生成 soapClient 代码,需要提供 wsdl 文件的 url 地址或者本地 wsdl 文件,而由于对方白名单现在,我本地无法请求对方服务器,于是想起了在服务器架设 nginx 正向代理实现本地调试。
找到服务器的 nginx 配置文件目录,新建一个 conf 文件,填入配置,意思是将收到的请求全部转发,由于原项目用的是域名 + https,所以这里增加个配置不会干扰原来的线上环境。
1 | server { |
然后原来的 wsdl 地址: http://222.xxx.xxx.116:7x00/service/xxx/query?wsdl 修改服务器的 ip 地址就可以访问了,也就是:http://47.230.xxx.xxx/service/xxx/query?wsdl ,浏览器访问成功。
本以为 IDEA 填写这个 wsdl 地址就可以,没想到,IDEA 解析 wsdl 后,会访问里面 xsd 的 schemaLocation 地址进行解析,这就尴尬了,这个地址无法代理啊。
然而,还是有招,我把 wsdl 文件下载下来,把 xsd 的 schemaLocation 地址改掉服务器 ip 地址就可以了。
jdk 1.8 生成过程有个坑,会出现乱码,需要往 jdk/jre/lib 目录下新建一个 jaxp.properties 文件,写入
1 | = all |
接着就可以顺利生成代码了,如下图:
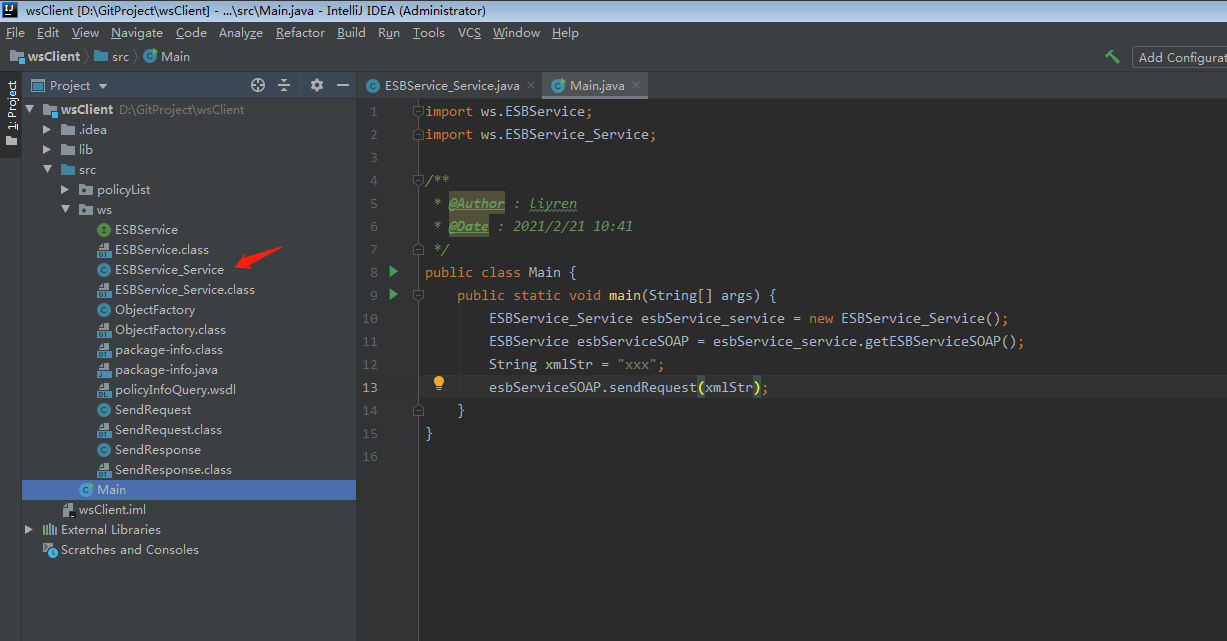
写个 main 方法调用生成的代码即可。
最近做一个 APP 后端重构的项目,由于项目没有详细文档,不清楚具体有哪些请求,请求的数据格式如何,只能自己用抓包工具去抓,网上配置教程一大堆,但其中还是踩了一些坑,绕绕转转,也花了半个小时才彻底解决,花点时间记录下,方便下次配置的时候,快速上手。
https://www.charlesproxy.com/download/
安装没什么的,就是下一步下一步搞定。
Proxy - Proxy Setting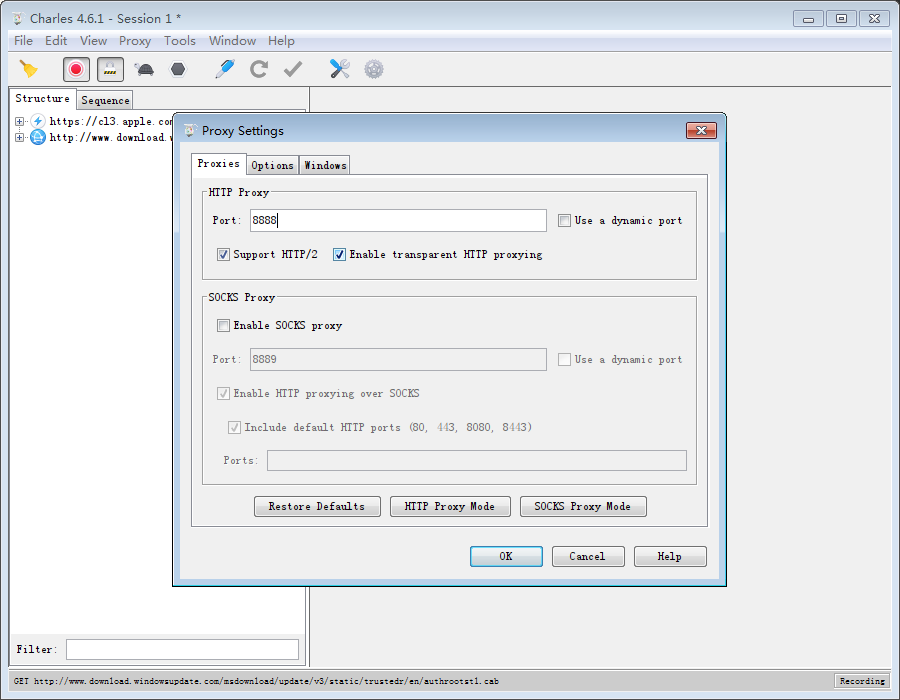
最近接了个 APP 重构的项目,后端是用 node.js 写的,数据存放在 mongodb,重构第一步是梳理清楚数据库设计,用 Navicat 设计好表后,要编写 markdown 格式的数据库设计文档,为了省时间,研究了一下表设计导出 markdown 表格,大大提高了效率。
1 | SELECT |
之前项目使用 kafka 有个 rebalance 报错的问题,折腾了好一会,后来搞明白是怎么回事,记录一下。
1 | 08-09 11:01:11 131 pool-7-thread-3 ERROR [] - |
这个报错是消费者在处理完上次 poll 的消息后,在同步提交偏移量给 broker 时报的错。初步分析日志是由于当前消费者线程消费的分区已经被 broker 给回收了,因为kafka认为这个消费者死了。
消费者在创建时有一个重要的配置max.poll.interval.ms,这个配置的意思是kafka消费者在每次 poll() 调用之间的最大延迟,消费者在获取更多记录之前可以空闲的时间量的上限。如果此超时时间期满之前 poll() 没有被再次调用,则消费者被视为失败,并且分组将重新平衡,以便将分区重新分配给别的成员。
那么简单来说就是,消费者消费速度跟不上,无法在指定时间内消费完上次 poll 的数据。
解决方法很简单,根据自身消费速度调整配置。
1、调大 max.poll.interval.ms
2、调小 max.poll.records
我最终选择了第二个办法,除此以外我还 review 了消费的业务代码,发现了一条慢 sql 拖垮了消费速度,所以最大的问题实质是慢 sql,优化后,完美解决这个问题。
原理:setKey 加锁;deleteKey 解锁。
问题:加锁的服务挂掉的话,锁无法释放,其他服务无法获取锁。
原理:setKey 加过期时间加锁;deleteKey 解锁。
问题:A服务获取了锁,但是业务操作时间过长,超过了 redis key 的时长,那么其他服务就会获取同一把锁。
原理:setKey + 线程ID 来加锁,同时起一个定时任务,当业务操作时间过长为 key 续命;解锁时判断 线程ID 是否来自同一个服务,是就解锁。
问题:解锁过程包含了取值、判断、删除key三个步骤,不是原子性会有并发问题。
原理:setKey + 线程ID 来加锁,同时起一个定时任务,当业务操作时间过长为 key 续命;解锁时用 lua 脚本的原子性来解锁,解决并发问题。
问题:redis 集群下不能用。
综上可见,redis 锁没有百分百的完美,但是版本四基本可以满足日常的使用需求了。
版本四 Spring 提供了实现方案:spring-integration-redis
mysql 支持四种事务隔离级别,每种事务隔离级别都各有优缺点。每隔一个阶段,都会对事务产生新的理解。
指当前事务可以读取到其他事务尚未提交的修改。此时会出现脏读的问题。
指当前事务只能读取到其他事务已经提交的修改。此时不会出现脏读的问题,但不能重复读,也就是同一个事务里面不能保证前后读取的数据是一致的。
指当前事务内每次读取的数据都是一致的,这是因为事务一开启,数据就上了写锁,其他事务不能再修改。此时不能保证幻读,幻读是由于事务并行处理导致的。跟 java 的并发处理一样的道理。而解决幻读的问题,一般交给上层语言,例如 java 的加锁操作,控制并发修改同一条数据。
序列化保证所有事务都是顺序执行的,就不会出现幻读的现象。
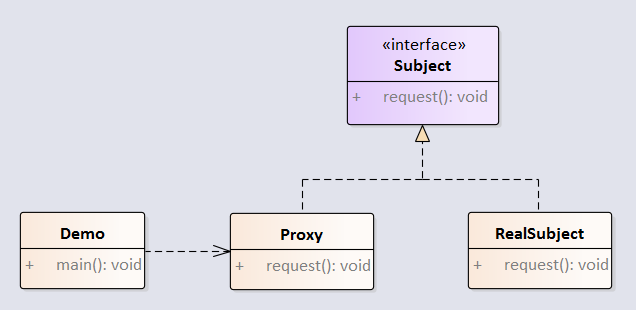
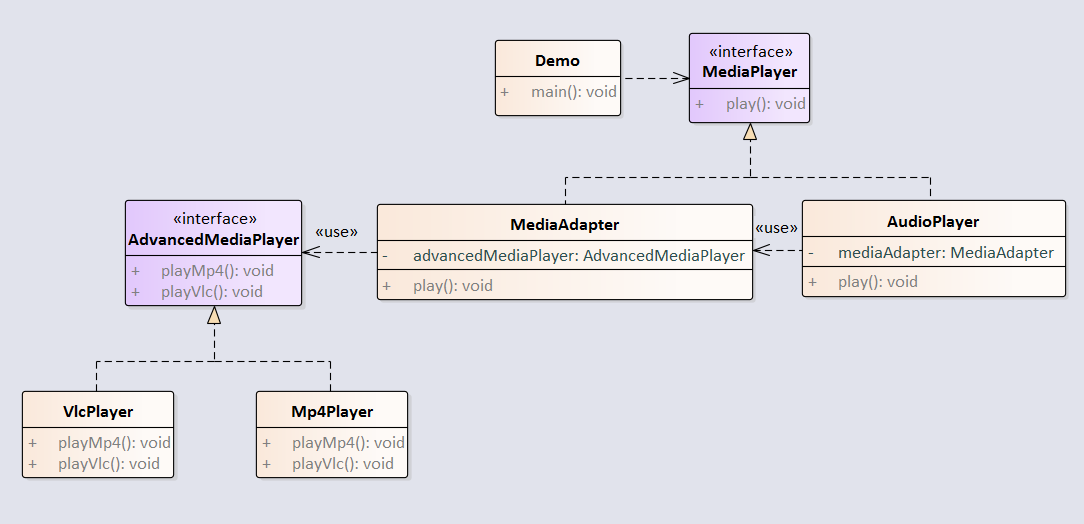
适配器模式将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
例子:音频播放器设备只能播放 mp3 文件,通过适配器来实现播放 vlc 和 mp4 文件。
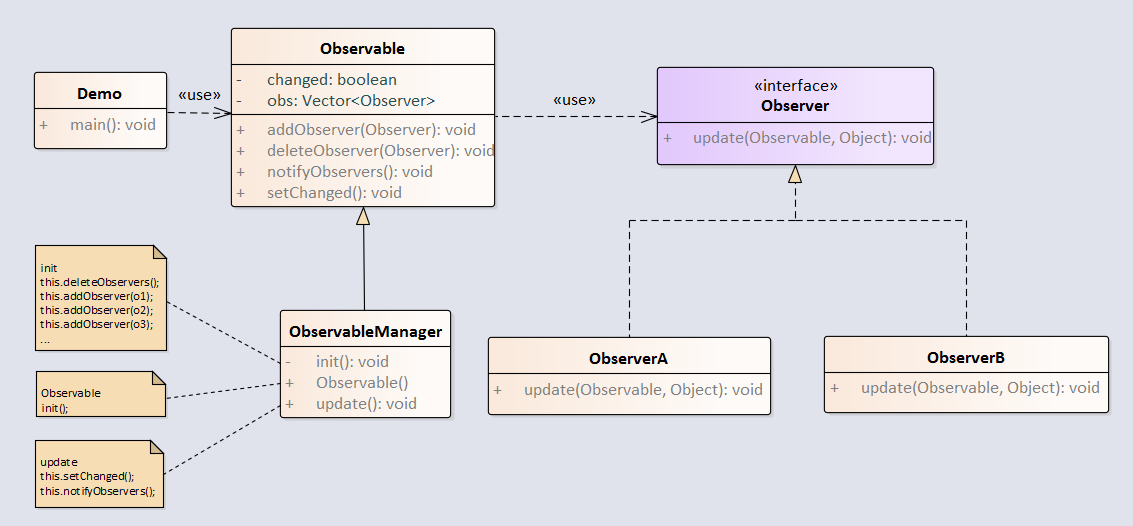
观察者模式用于一对多的对象关系中,当一个对象被修改时,会自动通知它的依赖对象。java中通过Observable类和Observer接口实现了观察者模式。
例子:
代理模式给某一个对象提供一个代 理,并由代理对象控制对原对象的引用。代理模式和装饰器模式、适配器模式很像,主要区别是装饰器模式为了增强已有对象的功能,而代理模式是为了加以控制。适配器模式主要改变所考虑对象的接口,而代理模式不能改变所代理类的接口。
例子: